
Project Coordinator (EU) :
Athens University of Economics and Business - Research Centre (AUEB)Country of the EU Coordinator :
GreeceOrganisation Type :
AcademiaProject participants :
This project is a joint effort between the Athens University of Economics and Business (AUEB) and the University of Memphis (UofM).
The AUEB members:
- Project Manager: George Xylomenos(M), Professor
- Technical Manager: George C. Polyzos (M), Professor
- Vasilis A. Siris (M), Professor, DID-related activities and the integration with NDN
- Nikos Fotiou (M), PhD, Researcher, DID-related tasks and security-related experiments design
- Yiannis Thomas (M),PhD, Researcher, NDN integrationand network-related experiment design
- Iakovos Pittaras (M), PhD student, execution of experiments
The UofM members:
- Christos Papadopoulos (M), Professor, running experiments on the NDN testbed and the UofM servers
State of US partner :
TennesseeStarting date :
Self-Certifying Names for Named Data Networking
Experiment description
The SCN4NDN project is experimenting with the merger of two promising NGI technologies: Information-Centric Networking (ICN) and Decentralized Identifiers (DIDs).
ICN has been on the spotlight of many research efforts for more than a decade. It has been explored as a standalone future Internet architecture, as well as an enabler for other NGI architectures, including 5G, the Internet of Things (IoT), and architectures focused on big data and/or cyber security. ICN’s main goal is to enable fast and secure content dissemination by leveraging direct and intrinsic information identification; this allows supporting multicast, multipath, and caching, as well as novel trust mechanisms. In this project we are experimenting with the Named Data Networking (NDN) ICN architecture.
A DID is a new form of identifier under standardization by W3C. A DID system can be regarded as a key-value lookup system, where the key is the identifier, the DID, and the value is a DID document. A DID document contains “properties” including information that can be used for verifying DID ownership, as well as the document's integrity. In this project we are experimenting with a self-sovereign DID system, i.e., a system where DID documents are managed by the DID owners themselves (as opposed to systems where DID documents are managed by a trusted “registry”).
The project is driven by the goals of improving ICN security, enhancing content-owner's privacy, and enabling decentralized data governance. To this end, the project is validating and evaluating a solution that uses self-sovereign DIDs to protect content authenticity in NDN. The integration of DIDs into NDN is expected to provide robust security against fake content (that is, content that does not correspond to its name) without relying on third parties, as well as efficient spam prevention. The project is specifically evaluating the use of DIDs as content name prefixes. These DIDs are randomly generated and do not reveal any information related to the (content) owner (as opposed, for example, to a digital certificate bound to an owner- specific identifier): this is expected to provide enhanced privacy and resilience against user censorship attacks, since it will not be possible to track and/or filter content belonging to specific owners. Furthermore, the project anticipates improved decentralized data governance by enabling content owners to specify and integrate into their content items lists of authorized storage nodes, as well as basic access control policies. The project vision includes achieving these goals without degrading key functionalities of ICN (and of NDN in particular), including support for advanced traffic management (such as multicast and multisource).
Based on feedback from the NDN community and from conference reviews, we extended our scheme to allow a DID to delegate control of content not only to a public key, but also to another DID. This allows the entity where control is delegated to periodically rotate its signing keys, without invalidating the delegation DID. Such an approach is applicable to Content Distribution Network (CDN) and IoT scenarios, as shown in the experiments section.
Implementation plan :
Our DID implementation is based on the specifications of “DID:self”, a DID method we have published in Mobile Multimedia Laboratory, “DID:self method specification"4 A Python3-based software library5 currently at TRL3, provides DID document (self-)management functionality by implementing the corresponding Cre ate, Update, and Readmethods. The Create method is used for creating the initial DID document, the Update method is used for modifying it (including key rotation), and the Read method outputs the final DID document and a proof chain that can be used for verifying the binding between a DID and the corresponding document. An application layer solution will combine our implementation with python-ndn 6, an NDN client library, to provide the desired functionality as follows. For each content item, the application will generate a public-private key pair from the Curve25519 elliptic curve. The public key will be then treated as a DID and will be used as the name of the content item. The private key that corresponds to a DID/content name, will be used for signing content item metadata. Metadata will include information that can be used for verifying various properties of an item, such as its integrity, version, type, and alternative names. Eventually, the DID document that corresponds to an item, the appropriate proof, and the signed metadata will be included in the payload of a NDN packet. Using python-ndn, the application will interact with the “NDN Forwarding Daemon” (NFD) of a testbed node in order to perform the appropriate (ICN) operations. Our final software will be at least at TRL4, and possibly at TRL5.
Our experiments will consider the following content item types: immutable items, mutable items that may have multiple “representations” (e.g., an image file stored under different encodings), and mutable items that may have different “versions.” When mutable items are used, we need a mechanism to distinguish among different versions or representations of the same item: this is achieved by including the corresponding information in the metadata (e.g., using a “version” and a “type” field). In addition, for mutable items, the DID document may specify the public keys of the entities that are allowed to generate new versions and/or representations of an item. Similarly, our experiments will consider two content delivery modes: the document mode and the channel mode.In the former mode, a content name will be mapped to a data “bucket,” e.g., an image file, whereas in the second case, a content name will be mapped to a data “stream,” e.g., a streamed video. During the project we will perform experimentsrelated tothe following ICN functionalities:
- Caching and Multicast Caching and multicast functionalitiesare provided by the NFD. Therefore, experimentation with these functionalities simply requires the allocation of a suitable topology within the testbed and the application of an appropriate workload at the endpoints.
- Multisource. In order to experiment with multisource, we will implement content name “aliases”. In particular, a content item will be provided by multiple sources and each source will use a different content name. All these name “aliases” will be included in a special field of the item’s metadata called “alsoknownas”. A client application will request simultaneously many of the item’s names, making sure that each request concerns different chunks. This will result in the client receiving different chunks of an item from different sources.
- Multipath. In order to experiment with multipath we will add a new node in the NDN testbed which will be attached to, at least, two nodes, located in different locations. Furthermore, we will allow the content owner to include in DID documents the public keys of in-network nodes that are authorized to modify “control fields” used for orchestrating multipath transmission
- Security. Our security related experiments will focus on detecting fake content. In particular,we will consider cases where an attacker signs a fake item using a revoked or a breached key.Our scenarios will consider various types of compromised keys, including keys allowed to update the DID document, as well as keys allowed to generate new versions/representations of an item.In our experiments we will “inject” fake content from various points of the testbed
4 https://github.com/mmlab-aueb/did-sel
5 Mobile Multimedia Laboratory, “DID:self method python library,” available at https://github.com/mmlab-aueb/did-self-py
6 Named Data Networking, “A Named Data Networking client library with AsyncIO support in Python 3,” available at https://github.com/named-data/python-ndn
Impacts :
With respect to the NGI initiative, our project is anticipated to have impact in the following areas:
- Enhanced EU –US cooperation in Next Generation Internet, including policy cooperation.
Beyond ICN, and ICT research in general, we believe that our project can be a starting point for better future EU-US relations in science and technology: both partners, AUEB and UofM, through their active collaboration in organizing international events, such as the ACM ICN conference, and their participation in international working groups, such as IRTF’s ICNRG, have already established a fruitful relationship that guarantees a successful collaboration. So far, we have collaborated with researchers from the Washington University in St. Louis, the Arizona State University, and the Tennessee Tech University (TTU), in order to extend the NDN testbed and co-operate in bug fixes and improvements of existing software. We made a git pull request to fix a bug in mini-ndn (https://github.com/named-data/mini-ndn), a package allowing NDN to run in the mininet emulator. Finally, we were asked by the NDN testbed maintainers to document our setup in a technical report, since the existing documentation has become obsolete due to changes in the testbed. - Reinforced collaboration and increased synergies between the Next Generation Internet and the Tomorrow's Internet programmes.
Our project combines EU-based and US-based researchers and resources to experiment with networking architecture and components that are of interest to both the Next Generation Internet and the Tomorrow’s Internet programmes. For instance, our “DID:self” method is applicable to a number of emerging authentication and authorization standards. Furthermore, our DID-based content authentication mechanism can be applied in other networking and application contexts, such as the emerging Inter-Planetary File System (IPFS) [9], network routing advertisements and even IoT scenarios using CoAP; our work in this area was published in two conference papers. We are monitoring such discussions in the NDN list, where many people involved with Tomorrow’ Internet are involved, and recently participated in a call on the NFD development list related to Verifiable Credentials (VCs). We are also discussing with Assistant Professor Susmit Shannigrahi from TTU the possibility of writing a joint paper on the evolution of NDN names with DIDs. We are also discussing with Dr. Dirk Trossen, Chief Network Architecture Research Engineer at Huawei, possible joint research directions. - Developing interoperable solutions and joint demonstrators, contributions to standards.
Our project is expected to be a showcase of the merger of two emerging standards, managed by different standardization bodies. On the one hand, DIDs are primarily pursued by the W3C. On the other hand, ICN technology is mainly developed under the umbrella of the IETF/IRTF. Both efforts involve partners from academia and industry. Beyond the demonstration of the joint standards, the project is anticipated to inspire new activities in the respective standardization bodies. In particular, we expect to ignite discussions related to self-managed DIDs, as well as to novel content authentication mechanisms. Therefore, in addition to releasing our software, we presented our approach to the NFD developers during their regular teleconference, where we gathered important feedback - An EU - US ecosystem of top researchers, hi-tech start-ups/SMEs and Internet-related communities collaborating on the evolution of the Internet
We envision that this project will not be a mere collaboration between two ICN pioneers but will also establish a permanent link between EU-US ICT research based on the Future Internet ICN approach. EU ICN research efforts are more human-centric, focusing mostly on security and trust, self-sovereignty, and distributed data governance. US efforts on the other hand prioritize deployment and real-world exploitation. We believe that research teams on both continents will benefit from this complementary partnership. The collaboration so far, which arose out of the needs to setup our experiments and update/fix existing tools, is quite promising.
Results :
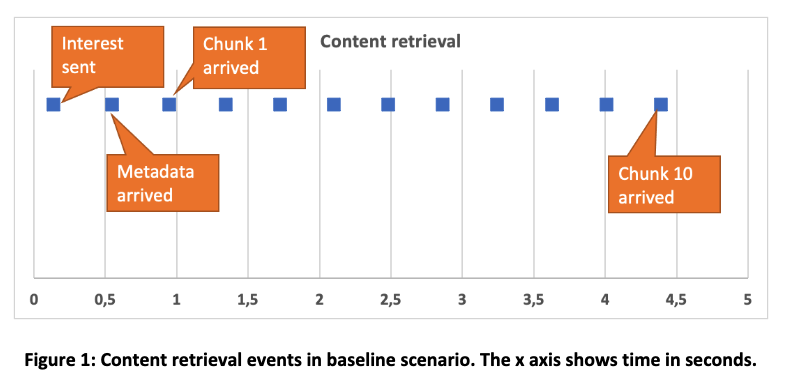
Our first set of experiments aimed to validate our concept. As a baseline scenario we performed the following experiment. We implemented a Producer script installed in an endpoint VM attached to the testbed node at Colorado State University (CSU), and a Consumer script installed in an endpoint VM at a MMlab testbed node. The Producer script advertises a content item name prefix. Initially, the Consumer script sends an interest message for that prefix (see Figure 1 for the sequence of events). After 0.5 seconds a packet arrives that includes the content item’s metadata. The metadata indicate that the content item includes 10 chunks. Then, the Consumer script requests chunks one by one, i.e., it requests the second chunk after the first chunk has arrived, and so forth. After 4.39 seconds all chunks have been received.
Scenario 1: Accelerated content retrieval using multisource transfer
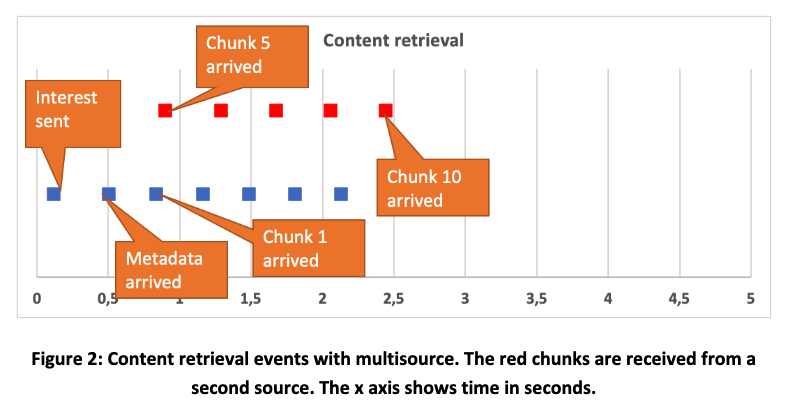
With this experiment we validated our approach of using multiple sources (multisource). In particular, we validated that it is possible to receive a content item simultaneously from two different sources (with chunks coming from both sources). For this experiment we extended our baseline scenario to include another producer, located at an endpoint VM attached to the testbed node of the University of Memphis (UofM). This producer advertises the same content item using a different name prefix; however, the two content items are linked through their metadata.
As in the baseline scenario, the Consumer script sends an interest message for the prefix advertised from CSU (see Figure 2 for the sequence of events). After 0.5 seconds a packet arrives that includes the content item’s metadata. The metadata indicate that the content item includes 10 chunks, as well as that the item has an alternative name. Then, the Consumer script requests half of the chunks using the original name, and at the same time it requests the rest of the chunks using the alternative name. After 2.43 seconds all chunks have been received.
Scenario 2: Recovery from network failure using multisource
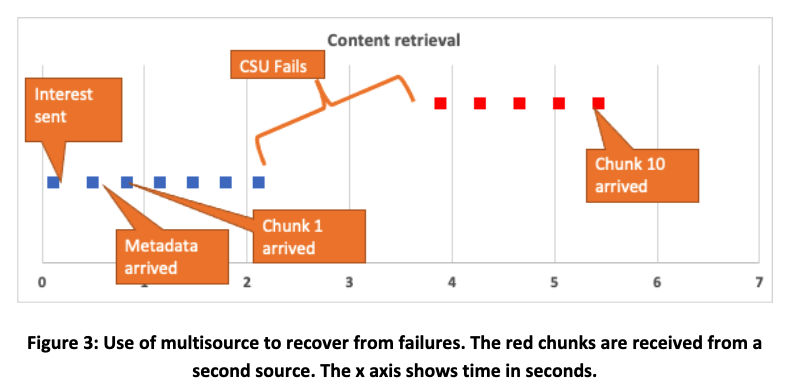
With this experiment we validated our approach of using multisource to recover from network failures at the application layer. The setup of this experiment is the same as in scenario 1. However, in this experiment the Consumer script uses the alternative name as a backup solution. The Producer script attached to CSU is configured to stop responding to new interests after transmitting the 5th chunk. At this point, the corresponding interest “times out” and the Consumer requests the rest of the chunks using the alternative name. After 5.49 seconds all chunks have been received, as shown in Figure 3.
Scenario 3: Application layer multipath
This scenario experiments with the use of multiple paths (multipath) which are exploited simultaneously for receiving an item. For this experiment, and similarly to Scenario 1, two alternative prefixes are used for the same item. Nevertheless, in this scenario both prefixes are advertised by the same producer. Therefore, the producer script advertises the two prefixes (prefix1 and prefix2) from a testbed node located in UMemphis. The Consumer script creates two faces: face1 is used for connecting to a MMlab testbed node and face2 is used for connecting to a CSU testbed node. Then, the Consumer script registers a route towards prefix1 through face1, and a route towards prefix2 through face2. The Consumer sends an interest message for prefix1. The first packet that arrives includes the content item's metadata. These metadata indicate that the content item includes 10 chunks, as well as that the item has an alternative name (i.e., the prefix2-based name). Then, the Consumer script requests half of the chunks using the original name, and at the same time it requests the rest of the chunks using the alternative name: requests for the alternative name are routed through face2, therefore they reach the publisher through an alternative path. With this scenario we obtain the same results as in the case of multisource (Figure 2), using however a single source.
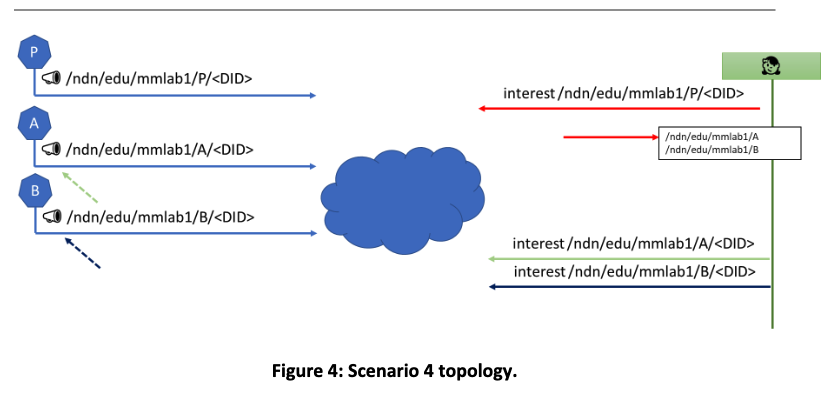
Scenario 4: Security attack
In this scenario we consider the setup of Figure 4. In particular, there are three Producer scripts, one attached to a CSU testbed node (producer P) and two attached to MMlab testbed nodes (Producers A and B). All producers are part of a service identified by a did:self DID. Producers A and B provide “IoT measurements”, published using the service DID as a prefix, whereas producer P publishes a “list of producers” also using the service DID as a prefix. Initially, the Consumer script, which is attached to a testbed node of UMemphis, sends an interest for an item advertised by P and receives the list of producers, i.e., it learns about producers A and B. Then, it periodically sends two interest packets, one for the measurements of producer A, and another for the measurements of producer B. We emulate an attack where an attacker gains access to the private key that producer B uses for advertisements (but not the private key that corresponds to the DID and used for signing Data) as follows: we initiate a new Producer script attached to the same node as the Consumer script; this Producer script (Attacker) is configured with the private key of B and sends an advertisement to the network. Since the advertisement is signed using a valid key, it is accepted. Moreover, since the attacker is attached to the same node as the Consumer script, the next interest sent by the Consumer script is satisfied by the Attacker. Meanwhile, we assume that the breach has been detected and producer B is renamed to producer C, and is configured with a new private key (used for signing NDN advertisements). Upon receiving the data packet from the attacker, the Consumer script fails to validate the signature (since this signature should be generated using the private key that corresponds to the DID, and the attacker does not have access to it). As a result, the Consumer script sends a new interest for the item published by publisher P, and it receives the updated list of producers.
Update of the design based on the feedback of the NDN community
In our initial design we were using did:self DIDs as content names. Nevertheless, after interacting with the NDN community it became clear that we can increase the compatibility of our approach with NDN semantics, without losing any of its desired properties, if we use did:self DIDs as content name prefixes.
In our updated design, we consider content producers that are responsible for advertising and publishing content items, and content consumers that express interest in content items. Content item names are hierarchical, and we consider two items with the same name as the same item. We also consider “protected” namespaces rooted in a DID, that is, the DID is the prefix of the namespace. These namespaces are owned by the corresponding DID owner.
With this update, a new property is added to the metadata of a content item, which indicates the item’s name. Our experiments are not affected, as it is only the interpretation of the DIDs that changes, and not the procedure for asking for and receiving content.
Exploration of new constructions during the extension
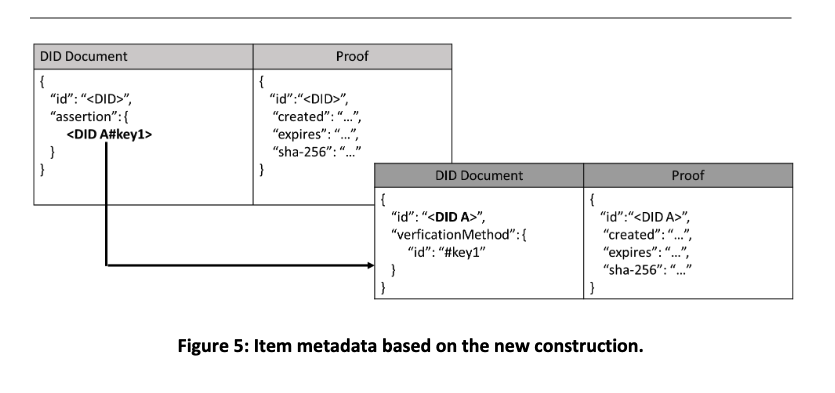
Our project was extended by 1.75 months, and this gave us the opportunity to explore an additional construction that facilitates “content storage delegation.” We performed the following experiment. A producer P owns the prefix /<DID> and wishes to allow producer A to publish a content item under /<DID>. Producer A owns a did:self DID, i.e., <DID A>, and in the corresponding DID document has defined a public key. Producer P enables delegation by a generating a DID document for <DID> that includes in the “assertion” property the identifier of the public key defined in the DID document of <DID A> (see also Figure 5) and by sending this document to producer A. The advantage of this approach is that producer A can change its public key without having to receive a new DID document from P. In a certificate-based system, this is the equivalent of being able to change keys without having to receive a new certificate.
Future Plan :
SCN4NDN is just a first step and many promising potentials of this approach still remain unexplored. In particular:
SCN4NDN leveraged did:self only at the application layer. However, core network components can benefit from this approach, especially given their information-centric operation. For example, a serious attack against NDN (and ICN in general) is “cache poisoning” where an attacker fills caches with fake items. Using our approach, such an attack can be prevented.
SCN4NDN tries to solve the problem of security key breaches only in “closed systems”, i.e., systems where “everybody talks with everybody.” However, a more general solution is required. SCN4NDN did not provide a solution for open systems since it did not want to make any assumptions about the ICN API of NDN. We can now state that by taking advantage of the NDN ICN API and its support for “versions” we can mitigate security incidents in open systems. Nevertheless, this possibility is yet unexplored.
SCN4NDN uses public keys as content name prefixes. Although this simplifies the security operations it still requires a secure way for disseminating these public keys. Therefore, using the SCN4NDN approach there are cases that still require a PKI system. Certificateless Public Key Cryptography (CPKC) can be a solution to this problem. CPKC improves Identity-Based Encryption by solving its inherent key escrow problem (i.e., the fact that there is an entity—the Key Generator—that knows all secret keys). • The SCN4NDN approach requires access to the whole content in order to perform content verification authentication. However, there are cases where it is desirable to hide parts of the content, e.g., because they include sensitive information. Consider for example the case of an electronic identity and the scenario where a service is interested in learning only the age of the user: a solution that allows hiding all fields but the age, but still makes it possible to verify the authenticity of the identity would increase significantly the privacy of the system. This problem could be solved by integrating Zero-Knowledge Proofs to our approach.